-
Simple is powerful. This is the unofficial motto behind dbt, which stands for Data Build Tool. With the complex problems that arise in the implementation of new technologies, a proper study of data always leads to statistical solutions.
As data analysts and engineers, we seek affordable tools that get the job done without much sophistication. Dbt is one of those tools that has helped engineers by allowing them to work with data in various warehouses more efficiently.
Databricks, another powerful tool, complements dbt in accomplishing these processes. As an Enterprise AI cloud data platform, the company has its roots back in 2013 when Apache Spark founders decided to expand their activities.
Seeing the massive use of SQL and the practicality it comes with, Databricks developers searched for ways to streamline its use throughout their platform with ease. Therefore, they came up with a native adapter for dbt, which allows clients to build seamless data pipelines on Databricks by writing lines of SQL code.
What is Databricks?
Databricks is a data lake that supports AI. After using other products such as Snowflake ,you might be curious about their differences. They both offer similar services but differ in their capabilities and their growth potential.
Snowflake is a data warehouse where you can store, manage, and work with data in a proficient way. However, Databricks offers much more than storing and managing data. It offers artificial intelligence solutions that allow the use of data to produce smart models.
Databricks is mainly focused on advanced large enterprise projects in the field of data science, such as Artificial Intelligence and Machine Learning. It is a cloud-based data platform that handles data transformation securely by making use of in-memory caching for rapid query execution that facilitates the processes even with large amounts of data.
Located in over 20 offices around the world, Databricks is growth-focused and it has delayed going IPO so that it can channel all the resources into expanding in multiple countries, offering completely localized service.
Source What is dbt?
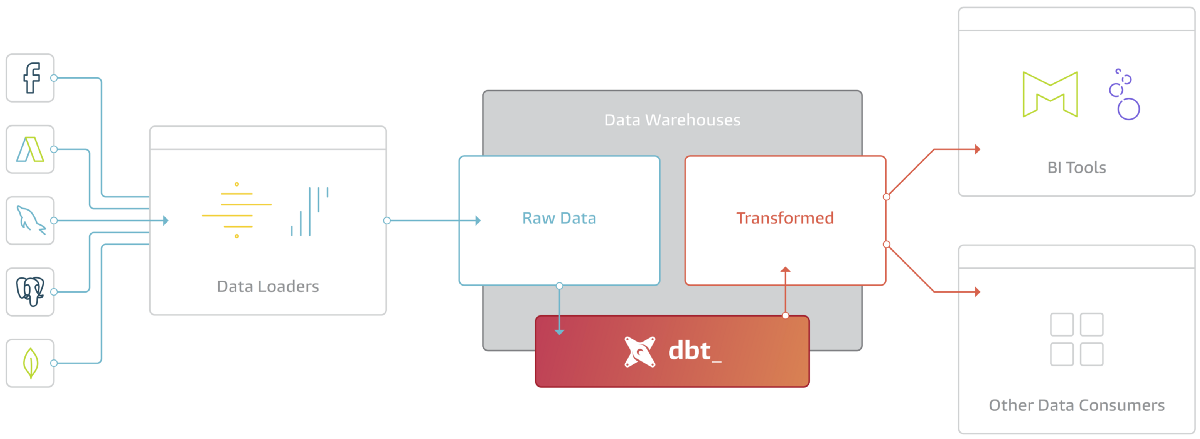
Dbt is an open source data modeling tool used by analysts and engineers for writing SQL queries. Building data pipelines is done faster since files are organized in folders and directories, just as plain text so deployment, testability, and version control are made simple.
Not only does dbt simplify complex queries, but it also reduces the need for repeatable lines of code. It turns queries into blocks of code that execute data transformation tasks inside your warehouse. Dbt runs code against the database, after compiling it into SQL.
To understand dbt, we must understand ELT. ELT stands for Extract, Load, and Transform. This type of architecture focuses on transforming data after loading. Dbt is the T in ELT. It transforms existing data in your warehouse, but it doesn’t deal with its extraction or load.
How do dbt and Databricks work together?
As a development environment, dbt users can run transformative commands on their data by writing only SQL select statements. Then, it’s the job of dbt to take these statements and build views and tables. Your code is compiled into raw SQL and runs against a specific Databricks database. There, users have access to version control, modularity, collaborative coding patterns, documentation, and much more.
The dedicated native adapter for Databricks can be installed comfortably by running pip- dbt-databricks. This package was developed by the programmers who founded dbt-spark and it’s open source for you to analyze and modify. Led by dbt Labs, all contributors worked on developing a package that is easy to install and doesn’t depend on ODBC drivers.
Three points worth noting during this adaptation are:
- Dbt models follow the Delta format primarily .
- Photon speeds up the work of expensive queries.
- Delta Lake’s MERGE statement is implemented with incremental models.
Final Thoughts
The dbt Labs team is continuously working on enhancing the functions of dbt and specifically its integrations with Databricks Lakehouse. Considered as an ideal environment for data warehousing activities, it offers optimal performance and understands commands written in standard SQL. Obviously, it accepts data pipelines based on dbt as well.
Blue Orange has a team of data scientists well-versed in analyzing and storing data in data lake environments and more. Our clients benefit from a faster extraction, ingestion, and transformation of data with maximal accuracy. Read further details here.

Deploying dbt on Databricks Simplifies Data Transformation Even More

Josh Miramant
Posted On:
May 26, 2022
May 26, 2022