




The software industry has seen immense changes in recent years thanks to the implementation of open-source, cloud, and SaaS business models. Data integration is done much more efficiently and effectively, supplying analysts and engineers with more time to spend on other important activities.
Setting a technology stack can be done in half the costs and time it took a few years ago, and businesses can continue running quickly. A “technology stack”, from which the term Modern Data Stack originates, stands for the set of technologies used to store, manage, and analyze data. These technologies are commonly based on cloud-based services and are available on low-code tools for broader access.
The Modern Data stack is focused on solving data challenges throughout its lifecycle in the cloud. This involves its journey throughout the cloud from the moment data is collected to its application in solving users’ problems. Data-based organizations have completely shifted how they position themselves in the industry.
For example, Airbnb is far from being a traditional hotelier and Stitch Fix can’t be compared with normal clothing retailers. These changes have also heavily impacted the careers of professionals working in the data industry, leading to the creation of new roles and increasing the demand for what were less-important roles.

What is Modern Data Stack (MDS)?
Traditional data platforms are ineffective in successfully managing large amounts of data due to their processing speed and complexities. Technologies that make up a Modern Data Stack rely on a cloud-native data platform. New technologies emerge but their categorization is made based on the same phrase of the data lifecycles.
- Data Ingestion (Fivetran, Stitch)
- A Cloud Data Warehouse (Redshift, BigQuery, Snowflake, or Databricks Delta Lake)
- Data Integration (Segment, Airbyte, Fivetran)
- ETL Data Transformation Tools (dbt)
- BI Layer (Mode, Looker, Periscope, Metabase)
- Reverse ETL (Hightouch, Census)
- Event Tracking (Segment, Snowplow)
The main purpose of a Modern Data Stack is to make data available for use as efficiently as possible and in minimal time. And there has been tremendous progress because data which took months to be available is now usable in a matter of weeks or even hours. Businesses may not need all components depending on their data processing needs to acquire this speed.
What’s The Difference Between a Legacy Data Stack and a Modern Data Stack?
The most prominent difference between the two stands in the configuration technicalities. A Modern Data Stack, unlike a Legacy Data Stack, is hosted on the cloud which means a lot less struggle for the users to configure and utilize the tools. This translates to facilitated access for end-users and accelerated scalability.
Achieving the same efficiency and meeting the data needs would require longer and more expensive processes needed to scale the local server instances. As a result, the technical barrier to the implementation of the Modern Data Stack is lowered, allowing a seamless data integration.
Modern Data Stacks are more inclusive since they are built with business users and analysts in mind. This allows users without a technical background to not only use these tools with a minimal learning curve but also administer them.
What Are The Benefits Of A Modern Data Stack?
The benefits of a Modern Data Stack are quite straightforward. It saves money, time, effort, and a lengthy learning curve, as well as removing the restrictions that exist for data teams. Compared to on-premise solutions, cloud computing and storage solutions used by Modern Data Stacks are much more affordable.
Using off-the-shelf connectors can save time and costs associated with the designing, building, and maintenance of data connectors. This means that your teams of analysts and data scientists will have more budget and time to spend on higher-value activities.
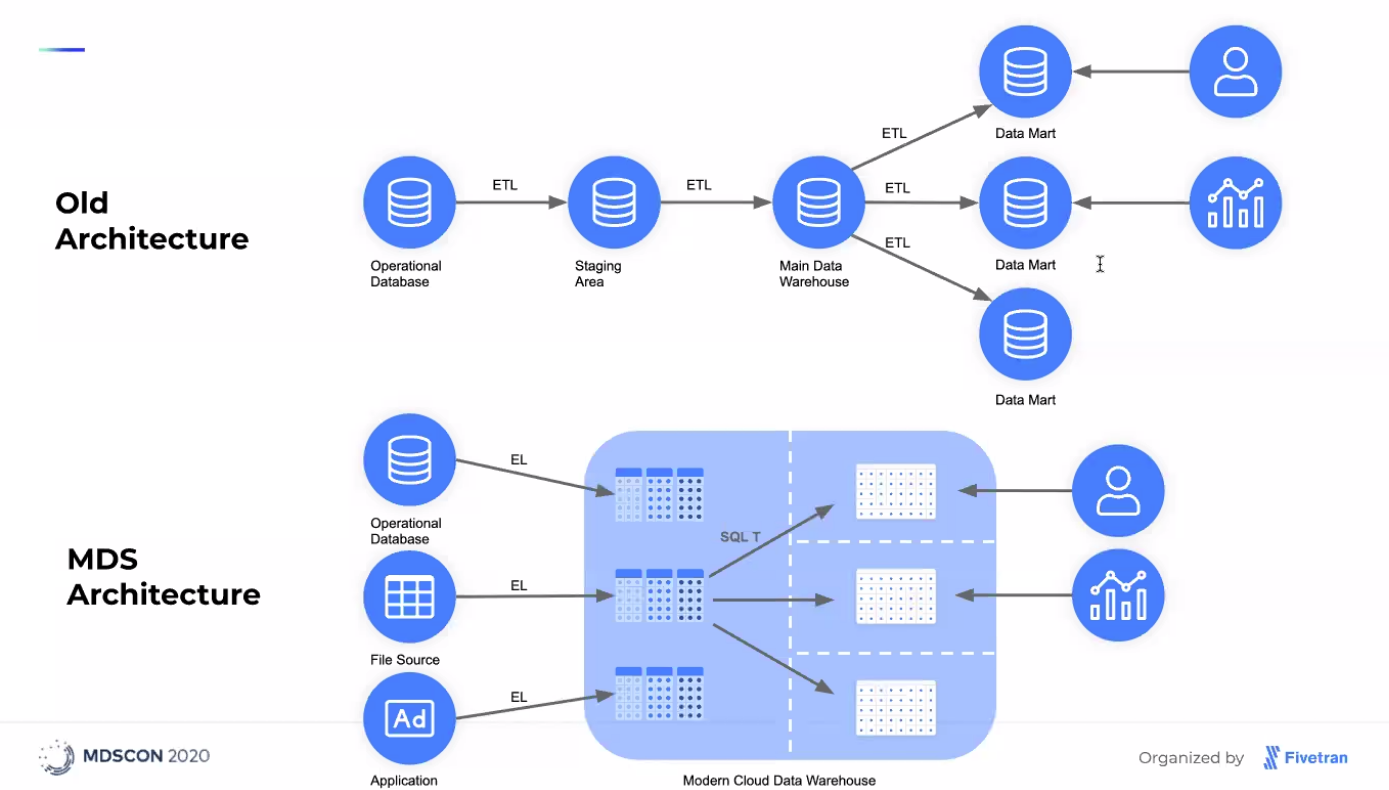
What Should Each Component of the Modern Data Stack Have?
The Modern Data Stack comprises four main stages through which data is processed: a data pipeline, destination, transformation layers, and a business intelligence/data visualization platform. Some features each component should have are:
Data Pipeline
In this stage make sure to choose a tool with prebuilt connectors that match your data sources. It will save time in the long term. Also, make sure the tool can be implemented easily for simplified data integration, scaling, and can be fully managed to allow a modification of schema and API changes.
Data Destination
Scalability is the main concern when it comes to choosing a data destination. The component should allow scalability in terms of storage and computing in a short downtime to support your analytics and storage requirements. Other things to be considered include the ease of setting up, running, and provisioning models.
Transformation Tools
The transformation tool you choose should be suitable for the chosen destination. It should also be equipped with the functionality of tracking your data lineage, and controlling its journey. The features could include the documentation and version control that are useful to track transformation results on your tables.
BI/Data Visualization
In this aspect the technical implementation which may involve variable defining for users, user accessibility, and visualization flexibility are important. Other considerations of the tool, such as the ease of self-serving it from a user perspective depends on the internal data structure.
Final Thoughts
The Modern Data Stack is evolving as new tools emerge and updated functionalities give more flexibility of use to data team members. Rapid growth equals more possibilities but companies still need expertise and time to make use of these developments.
At Blue Orange Digital, we work with dbt, Snowflake, and AWS Sagemaker among other Modern Data Stack technologies to implement data integration and visualization solutions for our clients. You can schedule a free 15 consultation with our data team experts here to learn more about our services.



