The conversation I have most often with operating partners starts the same way. The portfolio company has a capable IT team, it is running on modern cloud infrastructure, and someone recently rolled out an AI tooling subscription across the organization. Leadership has declared the company AI-ready. The investment committee memo reflects it.
Then we open the architecture.
What follows is almost always the same inventory: revenue reporting that takes three or four people three days to produce every month, data scattered across five disconnected platforms with no single source of truth, pipelines that fail silently whenever an upstream system changes a field name, and no mechanism to tell you whether any deployed model is actually doing what it was built to do. The company is not AI-ready. It is model-aware, which is a different thing entirely.
This distinction is where most stalled AI initiatives in PE portfolios actually live. Funds are committing real capital to AI value creation plans. An AI plan has become table stakes in the IC discussion, with some large sponsors reporting that 30 to 40 percent of IC discussion centers on whether a portco can deploy AI for productivity and growth or faces disruption. But the failure mode is not choosing the wrong model. It is building on an architecture that was never ready to support one.
After hundreds of PE-backed engagements and more than 250 production deployments, I have seen this pattern often enough to describe exactly where the gap lives.
The architecture, not the model, decides whether an AI initiative ships.
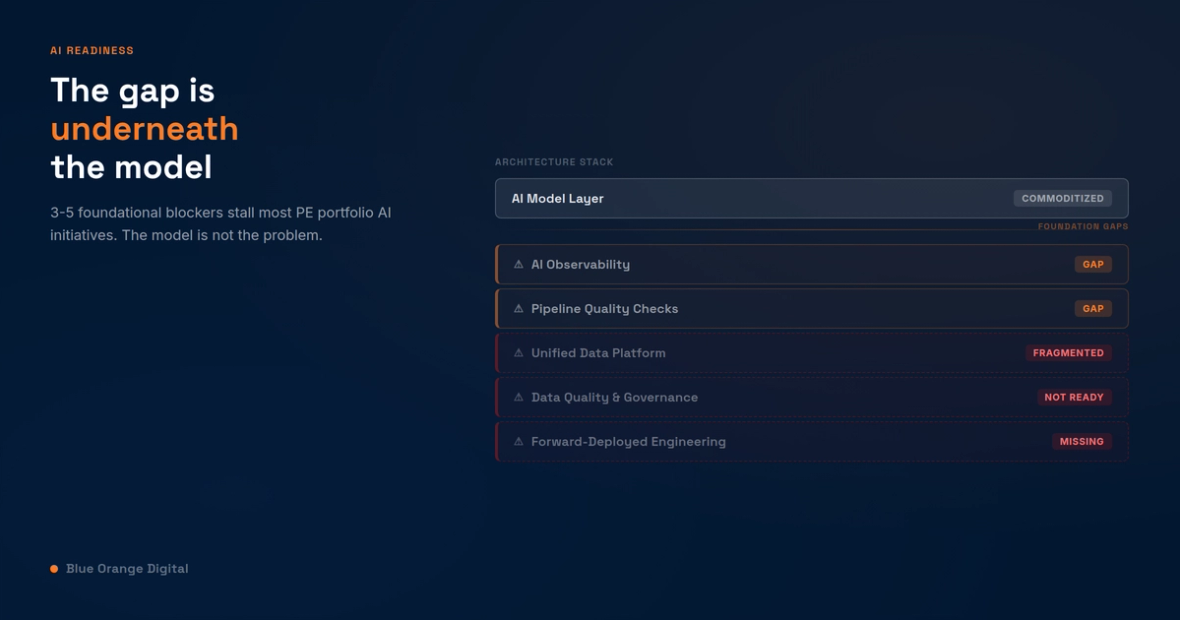
What the Architecture Actually Shows
The standard AI readiness conversation focuses on the model layer: which LLM, which vendor, which use case to prioritize. That conversation is a distraction for most mid-market portfolio companies. The model layer is the most commoditized part of the modern AI stack. What sits underneath it is not.
When we run an architecture assessment across a portfolio company, we look for five foundational blockers. Most companies have three to five of them.
The first is data quality and governance. This sounds obvious, but the depth of the problem usually surprises people. It is not that the data is dirty in one place. It is that no one owns the definition of "customer" or "revenue" across the organization, that two systems of record have been allowed to diverge across years of acquisitions, or that the data team has been building reports manually because no one ever formalized the pipelines. An AI agent reading this data does not hallucinate. It faithfully executes on incorrect inputs, which is worse, because it produces output that looks finished and authoritative.
The second blocker is fragmented platforms. Most mid-market portcos have assembled their data stack through a combination of acquisition, organic growth, and vendor decisions made without architectural oversight. The result is a Salesforce that does not talk to the ERP, a Snowflake or Databricks instance that holds some data but not the data anyone needs for meaningful AI use cases, and a reporting layer that stitches things together manually each month. Agents need connected, consistent data. Stitched data breaks agents.
The third blocker is pipelines without quality checks. The data moves, but no one monitors it. When an upstream system changes a schema, the pipeline fails silently. When a report lands incorrectly in the data warehouse, no one knows until a finance analyst opens the numbers on Monday morning. Organizations that have solved this problem have data observability tooling in place: automated alerts, schema validation, lineage tracking. Most portcos do not. For AI deployments that depend on fresh, accurate data to function correctly, a broken pipeline is not a data problem. It is an outage that the system cannot even report.
The fourth blocker is no observability at the AI layer itself. This is the gap that surprises senior teams most. When a company deploys an AI model in production, what mechanism tells leadership whether it is working? Click-through rates? User satisfaction surveys? Those metrics are blind to the actual quality of AI behavior. The right measurement unit for an agentic deployment is the run: the delegated task, the steps the agent took, the tools it touched, the corrections it needed, and whether a human actually accepted the output. Companies that cannot answer "what did the agent do and was the result trusted?" cannot improve the system, cannot catch compounding failure modes before they surface, and cannot demonstrate AI ROI in any meaningful way.
The fifth blocker is the missing forward-deployed engineer. This is less talked about in IC discussions, but it shows up in almost every stalled deployment. A forward-deployed engineer is the person who sits between the AI system and the business workflow, who understands both deeply enough to make the deployment actually work, to debug production failures before they become incidents, to identify the next automation opportunity, and to build the institutional capability that sustains the investment beyond the initial project. Building AI capability into a portco is not a single hire. It is a team, and this is the hardest role to staff. Most portcos either skip this function entirely or assume their existing data team covers it. It does not, and they cannot.
What "Ready" Actually Looks Like
The prerequisite for any agentic AI value is governed data: clean, documented, trusted, and moving through automated pipelines.
When organizations have this in place and apply agents to financial reporting workflows, they cut reporting time by 60 to 80 percent. The team that spent three days producing reports manually is now spending three hours reviewing outputs and acting on the analysis. When organizations deploy agents on ungoverned data instead, the agents produce erroneous output at scale, faster than humans could produce it manually. The math is not subtle.
Governance is not a compliance exercise. For an AI deployment, it is infrastructure. It means knowing what data you have, where it lives, how it moves, what it means, and who owns its accuracy. It means data contracts between the systems that produce data and the systems that consume it. It means pipelines that alert when they break and logs that tell you what failed and why. A portco with this foundation can build on top of it. A portco without it is running experiments, not deployments.
The companies I have seen exit at the top of their range share one characteristic across the data and AI dimension: their data is boring. It is clean, automated, and trusted. No one argues about the numbers in the monthly business review. The revenue report does not take a team three days to assemble. The finance team is spending its time analyzing the business rather than reconciling spreadsheets. That boring, reliable foundation is what makes AI actually work at the deployment level, not the demo level.
Why the Board Deck Says "AI-Ready" While the Architecture Says Otherwise
The gap between how AI readiness appears in a board deck and what it looks like in an architecture assessment is one of the defining problems in PE investing right now.
The board deck says "AI-ready" because the company has made AI tool purchases, has a stated AI strategy, and has seen demos that looked impressive. None of these things are readiness. They are interest.
An AI plan is expected in the IC memo, and that is a reasonable expectation. But an AI plan built on an unassessed architecture is a plan with an unknown blocker count baked into the capital allocation decision. I have walked into enough 100-day planning sessions to know what it looks like when a fund discovers the blockers after the thesis has been written: the timeline slips, the first use case gets descoped, and someone has to go back to the LP presentation to explain why the AI initiative did not move as fast as projected.
The board-deck-versus-architecture gap is not dishonesty. It is that the right assessment questions were never asked. "Do you have a data governance framework that is actually enforced?" is not a standard diligence question for most middle-market processes. "What is your financial reporting lag, and what specifically causes it?" is not either. "Do you have observability on any deployed AI models?" is asked by almost no one. The result is that portcos arrive at the value-creation phase with a full AI agenda and an infrastructure that cannot support the first initiative on it.
How to Assess Readiness Objectively
The right assessment for AI readiness is benchmarked and specific, not a confidence check from the C-suite.
Benchmarked means the portco's architecture is measured against what is typical for companies at the same stage and in the same vertical, not against an idealized standard that no mid-market company meets. The relevant question is not "is the data architecture perfect?" but "is it ready for the use case?" A company that scores well on data governance but has fragmented platform tooling requires a different intervention than a company with clean data but no observability. The blocker map decides the roadmap.
Specific means the assessment produces a named list of blockers, not a readiness score. Scores are for benchmarking conversations. Blockers are what the operating plan needs to address. The difference between a 62 and a 74 on an AI readiness index tells you nothing actionable. "Revenue data does not have a single source of truth because the ERP and the CRM have diverged, and the finance team resolves the discrepancy manually each month" tells you exactly what to fix and in what order.
Blueprint, the AI readiness assessment tool Blue Orange Digital built for PE portfolios, runs in about ten minutes without requiring infrastructure access. It is read-only, benchmarked against our delivery history across hundreds of engagements, and produces an immediate PDF with a named blocker list. The design is deliberate. Knowing you score a 64 does not help you build a 100-day operating plan. Knowing your three critical blockers, ranked by impact and sequenced by dependency, does.
What your AI readiness score actually tells you
Most operating partners look at the composite score first. A single number fits in a deck. But the composite is not where the useful information is.
The five dimension sub-scores are. Each one tells you something specific about what this portco's path to AI production actually requires.
I worked with a portco last year that came in above the sector median on four of the five dimensions. The fifth was governance, and it scored low. That single sub-score dictated the entire first six weeks: access controls, data ownership documentation, accountability structure. The composite looked like a green light. The governance sub-score was the real constraint.
Here is what each dimension tells you.
Data quality measures whether the data that will feed AI systems is consistent, documented, and trustworthy at the source. A low score means models will ingest unreliable inputs and produce outputs that drift from reality in ways that are hard to detect in production. Fix the data layer before adding AI tooling. Fixing it after models are deployed costs several times more.
Pipeline architecture measures whether data moves reliably between systems. A low score means data flows that break silently, fail under load, or run without built-in quality checks. AI agents that depend on fresh, accurate inputs produce inconsistent results when the pipeline underneath them is not stable. Instrument and harden the pipelines before deploying production agents.
Governance measures whether there is clear ownership of data definitions, access controls, and AI output accountability. A low score creates compliance exposure and makes it difficult to validate AI decisions at scale. Most operating partners categorize governance as a compliance matter. For an AI deployment, it is also infrastructure.
Tooling and platform utilization measures how much of the existing data platform is actually in use. Most mid-market portcos run their licensed platforms at 45 to 65 percent of available capacity. A low score here does not mean the company needs more tools. It means the current investment is not configured and adopted. Adding AI capability on top of underutilized infrastructure compounds the existing waste rather than building on something solid.
Talent measures whether the people exist to build, deploy, and maintain AI systems. A low score can reflect two different problems: a capability gap, where the right skills are not on the team, or a capacity gap, where the skills exist but are fully committed to keeping existing systems running. Blueprint surfaces which problem you are dealing with, because the interventions are different.
Reading the pattern across all five dimensions is where the sequencing decision comes from. A portco that scores low on data quality but high on everything else has a clear starting point and a predictable path. A portco that scores low on governance and talent at the same time has a harder problem: governance requires people to implement it, and talent takes time to bring in. The composite score does not show you this. The sub-scores do.
The Blueprint Assessment scores all five dimensions automatically in about ten minutes, without requiring infrastructure access. It produces a named blocker list mapped to your score profile. That list is what the 100-day operating plan needs to address, not the composite number.
From Readiness to Production: The 100-Day Path
Mapping the blockers is what makes the next 100 days a real plan rather than a general commitment.
Once a portco has a clear blocker inventory, the value-creation sequence becomes tractable. You address data governance and pipeline observability first, because every AI initiative downstream depends on them. You build or hire the forward-deployed engineering function, because the deployment will not survive production without the bridge role. You scope the first AI use case to a domain where the data is already clean, so the first deployment demonstrates real ROI rather than surfacing infrastructure problems at the worst possible moment in the hold.
This sequencing is the structure behind EDGE, Blue Orange's delivery framework for taking a portco from readiness assessment through production. The Assess phase maps the blockers. The Deploy phase ships the first production use case with the infrastructure fixes running in parallel. The Scale phase extends the initial deployment to additional workflows and domains. The Advisor layer sustains the capability through the remainder of the hold. The framework targets AI in production in 100 days, with outcome-aligned pricing, because the blocker map makes the path specific enough to hold to that timeline.
Across engagements covering 3 to 15 portfolio companies per fund, the pattern repeats: the funds that move from assessment to production fastest are the ones that did not skip the architecture review. The ones that stall are the ones that went straight from "the model is impressive" to "we are building."
What to Do Now
The funds I have seen build durable AI value across their portfolios share a discipline that is less common than it should be: they assess before they plan.
They do not ask "which AI use case should we prioritize?" before asking "what does the current architecture actually support?" They do not write an AI value-creation plan before identifying the blockers that will kill it. They do not leave a portco's AI readiness to self-attestation in a management presentation.
If your current AI plan for any portfolio company is based on a CEO's confidence rather than an architecture assessment, you have an unknown blocker count built into a capital allocation decision. That is a solvable problem, and it is faster to solve than most operating partners expect, but only after you know what the architecture actually contains.
Run the Blueprint Assessment and see where your portfolio stands.