Every portco engagement starts the same way. The CEO walks us through the data story. There is a business intelligence tool with a recognizable logo. There is a data warehouse that someone chose two years ago. There is a dashboard that appears in the board deck, which leadership treats as the authoritative number. "Data is not our problem," they say.
Then we open the stack.
What we find, consistently, is that data maturity is not what the leadership team thinks it is. Not because anyone is hiding anything. Because the inputs that feel like data maturity (a data warehouse, dashboards, a data team on the org chart) are not the same thing as actual data maturity. In a PE-backed company during the hold, that distinction is material: a Tier 1 data posture typically carries 20 to 40 percent in recoverable cloud cost, 45 to 65 percent of platform capability going unused, and 3 to 5 hard blockers to any meaningful AI deployment. None of that shows up in the board deck where leadership graded themselves.
This is the diagnostic we run when a portco says their data is fine.
Why the self-grade runs hot
Ask a leadership team to rate their own data maturity and they will typically land a tier above where they actually are. This is not a character problem. It is a measurement problem.
The signals they use to grade themselves are input signals: they have a data warehouse license, the BI tool is live, dashboards exist. But input signals do not tell you whether the warehouse is the system of record or the system of manual override. They do not tell you that finance and operations are producing different revenue numbers from the same underlying source. They do not tell you that the dashboards are referenced in the board meeting and quietly ignored on Monday morning because someone already knows the real number from the spreadsheet.
The diagnostic is not "do you have the tools." It is "what do the tools actually do, and does anyone trust them."
The five-area data maturity assessment
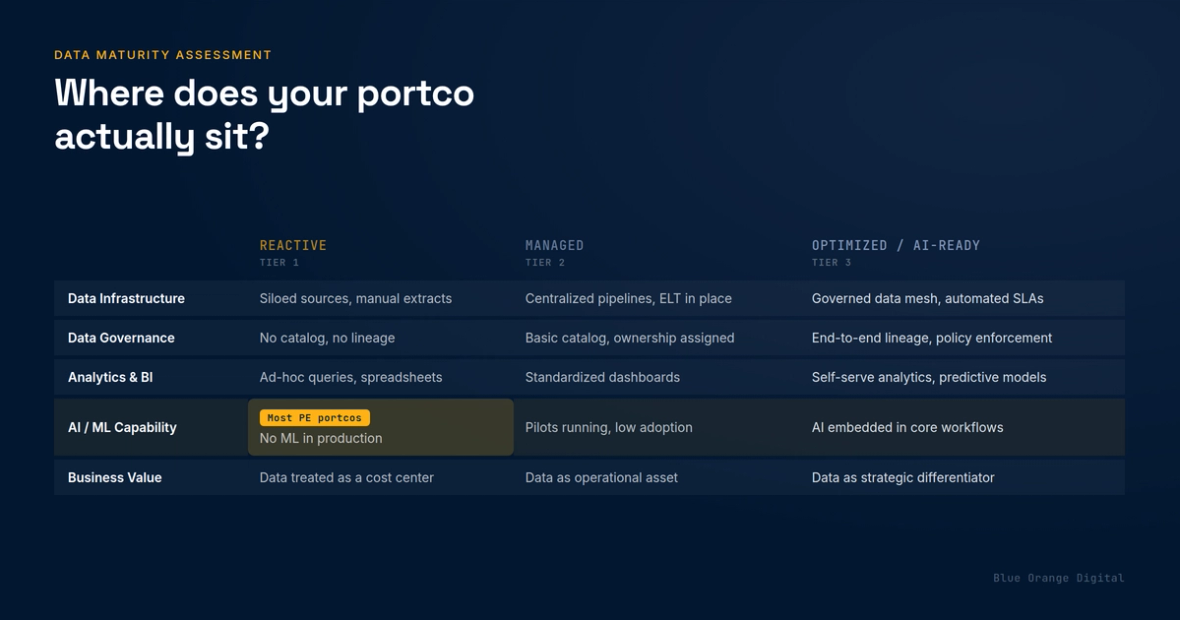
We assess portco data maturity across five areas. Within each, a company sits in one of three tiers: Reactive (Tier 1), Managed (Tier 2), or Optimized and AI-ready (Tier 3). Most portcos entering a hold are Tier 1 or early Tier 2 across the board. The gap between how they describe themselves and where they actually sit tends to be one tier. The self-grade runs exactly that hot, consistently.
Data quality
Tier 1 looks like this: revenue and operational data require manual reconciliation across systems every month, finance and operations routinely disagree on the numbers, and reports are assembled by people who have learned to distrust the data but do not say so in the board meeting. Tier 2 means there are defined owners for core data entities (customer, product, transaction) and reconciliation is at least semi-automated. Tier 3 is where data quality is monitored in real time, anomalies surface before they reach a report, and the business operates from a single trusted number that no one in the room argues about.
Pipeline architecture
Tier 1: data moves via manual exports, brittle custom scripts, and scheduled jobs that a single engineer built and no one else fully understands. Pipelines break silently. A schema change upstream creates a gap in the data that no one catches until a meeting two weeks later. Tier 2 means ELT pipelines are in place, basic monitoring exists, and new data sources can be added without a major rewrite. Tier 3 is pipelines that are modular, documented, and observable: data lineage from source to dashboard is traceable, new integrations take days not weeks, and the architecture can support agentic workloads without being rebuilt first.
Governance
Tier 1: no one formally owns data governance, there is no catalog, access controls are informal, and a compliance request creates a fire drill. Tier 2 means a data dictionary exists even if incomplete, access is managed by role, and there is a policy for sensitive data even if it is not consistently enforced. Tier 3 is a maintained data catalog, column-level security where the workload warrants it, and a governance framework that supports regulatory requirements and audit-readiness. The companies that arrive at AI deployment without Tier 2 governance in place spend the first phase of that deployment answering "where does this data come from" rather than deploying anything.
Platform utilization
Tier 1 looks like a Databricks, Snowflake, or Fabric contract purchased at the recommendation of a prior consultant, running at a fraction of its designed capacity, with unmanaged compute costs accumulating monthly and licenses that have never been right-sized. Tier 2 means core platform features are active, cost management is in place, and the team can articulate what it is and is not using. Tier 3 is the platform running at the workload scale and capability it was designed for: feature adoption is tracked against the roadmap, cost per workload is measured, and the team evaluates new platform capabilities proactively rather than reactively.
Talent and operating model
Tier 1: the data function is one generalist, reactive, building what is asked and fixing what breaks, with no structured path for business stakeholders to request and prioritize work. Tier 2 means differentiated roles (engineer, analyst), a backlog with a prioritization process, and a defined channel for business requests. Tier 3 is the data function embedded in business domains rather than siloed in a single team, with data leadership that has a real seat at the table, and a team that spends meaningful time on instrumentation and governance rather than ad hoc report maintenance.
The signals that matter, and the vanity signals that mislead
Three things that look like data maturity and are not:
Having a data warehouse is not data maturity. The relevant question is whether the warehouse is the system of record or the system of manual override. Most Tier 1 portcos have both, which means they have neither.
Having a data team is not data maturity. A team that spends 80 percent of its time responding to ad hoc data requests is a Tier 1 team regardless of headcount. The relevant question is what the team actually builds versus what it pulls.
Having dashboards is not data maturity. The relevant question is whether the business uses those dashboards to make decisions, or whether someone already has the real number in a spreadsheet by the time the meeting starts.
The signals that actually count: how long does a new metric take from concept to production? When data is wrong, how quickly does the organization know? When leadership asks a new business question, can the data team answer it inside a week?
Prioritizing by effort and EBITDA impact across the hold
Not everything needs to be fixed at once, and not everything carries equal EBITDA leverage.
The prioritization we use in our EDGE engagements: fix trust and reliability first. Data quality and pipeline problems compound everything downstream. A Tier 1 quality posture means every downstream initiative (reporting, planning, AI deployment) rests on an unstable base. Fixing it is the prerequisite, not the first visible win.
Through the middle of the hold: governance and platform right-sizing. Getting governance right before AI deployment is not optional. Platform right-sizing alone consistently surfaces 20 to 40 percent in recoverable cloud cost. We have watched portcos with clear AI ambitions spend the first half of their AI engagement establishing data ownership rather than deploying models.
Heading into the exit window: the Tier 3 operating model and AI readiness. The optimized state, where data is embedded in business domains and the platform is running at designed capability, is what creates the AI-ready posture that shows up in the next buyer's data room. For the deal-stage picture of what that buyer actually looks for, our data due diligence framework covers the six-dimension approach we use before close. And for what AI readiness looks like once these five areas are in shape, the AI readiness breakdown covers the architecture and the blockers in detail.
Running the full diagnostic
The checklist above is a starting point. A complete data maturity assessment for a PE-backed company adds benchmarking: how does this portco stack against peers in the same sector, revenue range, and data stack profile? Which gaps are tractable within the hold, and which require structural investment?
That is what Blueprint does. It is the productized version of this diagnostic: a 10-minute questionnaire, no infrastructure access required, zero data movement, benchmarked against sector peers, with an immediate PDF scored across the same five areas. The assessment runs without touching your data, and the PDF lands the same session.
If you are an operating partner evaluating a portco, or a management team trying to understand where you actually stand before the next board conversation, it is the fastest path from "data is fine" to a scored, prioritized starting point.
Run the full Blueprint Assessment in 10 minutes, free. Start here.
Run the checklist on your next diligence pass, then keep the intel coming. The Cliffside Chronicle sends operating partners a curated read on AI, data, and PE value creation every two to three weeks, built from live portfolio engagements. Subscribe here.