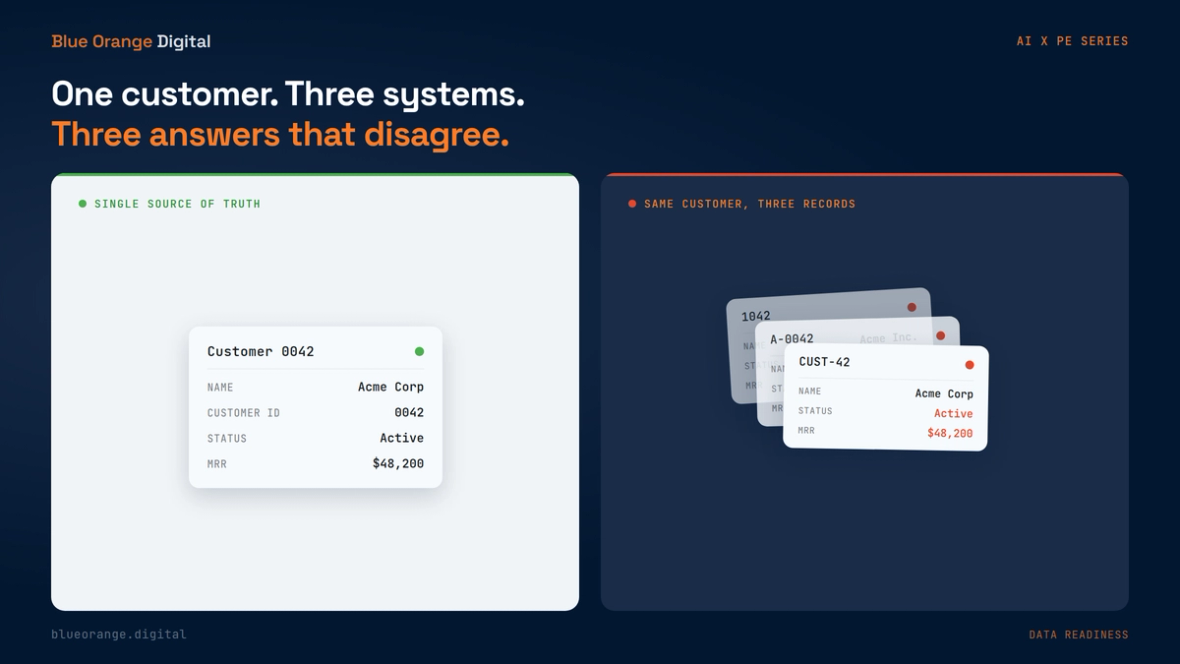
A mid-market services platform greenlit an AI initiative across three operating units after a strong vendor demo. The board liked the projected margin lift. The GP liked the timeline. Six months later, nothing had shipped to production.
The model was never the problem. The same customer existed under three different IDs across three systems, and no one had reconciled them. Every output the model produced was wrong in a way the business could not trust, and no one could say which version of a customer was real. The team spent the quarter arguing about whose numbers were right instead of deploying anything.
This is the pattern operating partners pay for again and again. The expensive mistakes happen before anyone picks a model. By the time the demo impresses the board, the deciding factor is already set: whether the portfolio company's data can support what the vendor promised.
Why AI Readiness Is a Data Discipline Problem, Not a Tooling Checklist
Operators who have run portfolio AI readiness before keep paying for the same two mistakes.
The first is deploying AI on top of fragmented, inconsistent data. A model that runs against records that disagree with each other will produce confident answers no one can defend. The cost surfaces late, usually after the build, when the business tries to act on an output and discovers the underlying numbers never agreed. The vendor rarely flags this, because the vendor sells the model, not the cleanup. Fragmentation stays invisible in a demo that runs on a curated sample.
The second mistake is treating AI readiness as a single-track problem. Readiness is not a tooling checkbox you clear by buying a warehouse and a model subscription. The real question is narrower and harder: can the company produce the same trustworthy number twice without a person rebuilding it by hand? A portfolio company can own every modern data tool on the market and still fail that test, because the discipline lives in how the data gets governed and produced, not in which logos sit in the stack.
Both mistakes share a root. Operating partners underwrite the data work too late, after the use case is chosen, when it should anchor the decision from the start. The diagnostic below moves that question to the front.
The Diagnostic Lens: Five Questions, One Working Session
You do not need a scored maturity model to run a useful data readiness assessment. You need five questions and one honest working session with the company's data leader. Ask each one directly and listen for the difference between a good answer and a warning sign.
1. Can the company answer one core business question the same way twice?
Pick a number the business runs on, like revenue by product line or active customer count, and ask two people to produce it.
Good answer: both arrive at the same figure from the same source, and they can point to it.
Warning sign: the numbers differ, and each person defends a different spreadsheet. That gap is the AI problem before it becomes an AI project.
2. How does that number get produced today, by a pipeline or by a person?
Good answer: a documented pipeline generates it on a schedule, and a person reviews it.
Warning sign: the close depends on heroics. One portfolio company needed four people and three days to produce a single monthly revenue figure. A company that rebuilds its core numbers by hand every month has nothing to automate on top of yet.
3. Who owns the data, and does the business actually trust it?
Good answer: a named owner answers for each core domain, and the operators who use the data believe it.
Warning sign: ownership lives in an org chart but not in practice, and the people downstream keep their own private copies because they do not trust the official one.
4. What happens when the data is wrong, and how fast does anyone notice?
Good answer: bad data trips an alert, someone owns the fix, and the company can tell you the last time it happened.
Warning sign: errors surface only when a customer or an executive complains. If no one catches wrong data until it causes pain, an AI system will scale that blindness.
5. Is the proposed use case sitting downstream of clean data, or on top of the mess?
Good answer: the use case draws on a domain the company already produces reliably.
Warning sign: the use case depends on exactly the data no one trusts. That is the most common and most expensive setup, because the demo hides it and the production system exposes it.
Five questions, one session. The answers tell you whether the portfolio company is ready to build or ready to fix first.
What "Ready Enough to Start" Actually Looks Like
The honest read often comes back mixed, and operators overcorrect in response. They hear "the data is not ready" and freeze the whole initiative behind a two-year overhaul. That is the opposite mistake, and it costs just as much in lost time.
Ready enough to start does not mean perfect. It means you have found one place where the data is already trustworthy and you build there first. The reliable starting point is usually a single-system reporting use case, where the data lives in one place, the pipeline already runs clean, and the business already trusts the output. A forecast built on one well-run system ships and earns confidence. A forecast that has to stitch together three systems that disagree does not.
The use case to avoid first is the cross-system one that depends on data no one has reconciled. That is the work, not the warm-up. When the highest-value opportunity sits on top of the mess, fixing one narrow data domain becomes the first deliverable, and you prove the pattern there before you widen it.
The operator's job is to find the high-trust starting point and sequence honestly from it. Not to stall on a full rebuild, and not to pretend the mess is ready.
How This Changes the Operating Partner's Playbook
Run the data read first, then scope the AI plan against what you find. Three moves follow from that. Whether you run this during AI operational due diligence before close or in the first hundred days after, the sequence holds.
Underwrite the data work as a line item in the AI plan instead of assuming it away. When the diagnostic surfaces a fragmented core, the cost of reconciling it belongs in the budget and the timeline from day one, not as a surprise the portfolio company absorbs mid-build.
Sequence the data work ahead of deployment. Put the narrow fix or the high-trust use case first, prove it, then widen. This is how a portfolio company shows a shipped result in a quarter instead of a stalled initiative at the next board meeting.
Set timelines against the data read, not the vendor roadmap. The vendor's schedule assumes the data is ready. Your schedule should assume what you actually found.
This compounds at exit. A portfolio company that turned a fragmented data foundation into a trustworthy one carries a higher multiple, because a buyer pays for AI that runs in production on data the team can stand behind, not for a pilot sitting on numbers no one trusts.
The Operators Who Get Returns Run the Data Read First
The firms getting real returns from portfolio AI are not the ones with the best models. Models are a commodity now, and everyone demos well. The firms getting returns are the ones whose operating partners ran the data read first, asked the five questions before greenlighting the spend, and scoped honestly from what they found. They treated data readiness as the first deliverable, not an afterthought. When the next vendor demo lands and the projected margin lift looks irresistible, the operator who has done this before asks the data question first. Then decides.