I was in a data room last quarter. The operating partner had brought us in because the portco wanted to deploy AI for revenue forecasting. Smart team, real use case, healthy budget. We spent the first two days not talking about AI at all.
We were trying to figure out how long it took to produce a clean revenue figure. The answer was four days and three people. Every month.
That is not an AI problem. That is a data problem that will kill any AI project before month three.
Across mid-market PE portfolio companies trying to deploy AI, the pattern is consistent: the model is almost never the bottleneck. The data underneath it is. And there is a fixed order to fixing that foundation. Skip a step and the project does not slow down. It dies.
The evidence is not ambiguous. Eighty-seven percent of AI proofs of concept never reached production, according to a session at the 2025 Databricks Data + AI Summit. The top reason was data quality. Not model capability. Not vendor selection. Data quality.
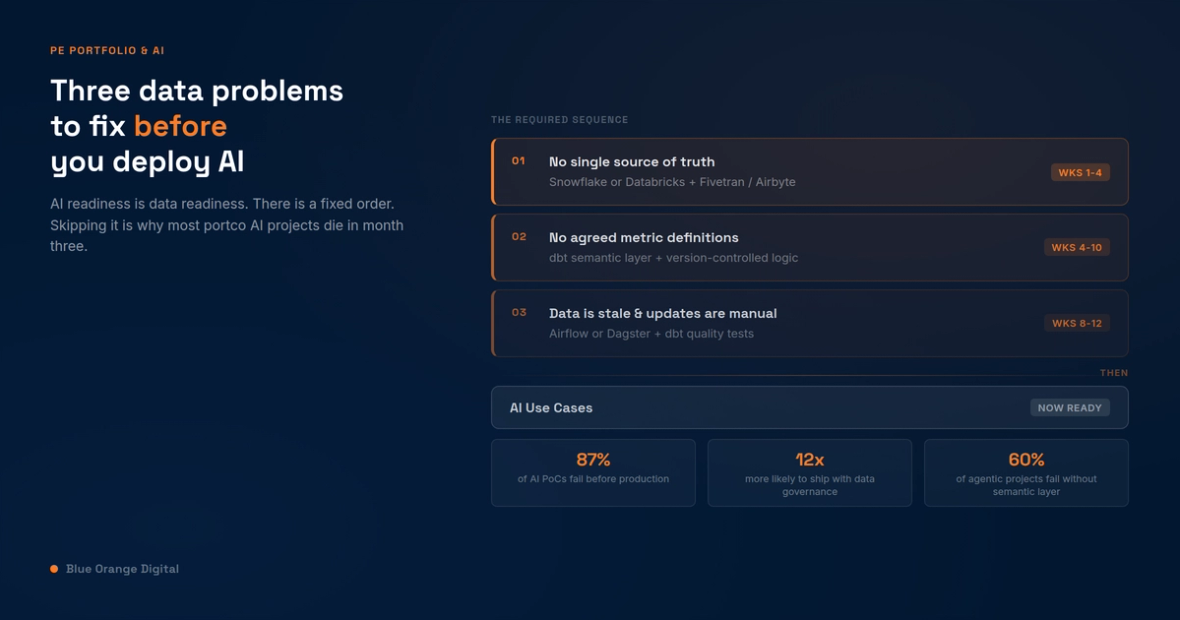
Fixing it comes down to three sequential problems. The portcos that work them in order get to AI by month twelve. The ones that jump ahead end up explaining to the board why month three looked so promising.
Problem 1: No single source of truth
Most portcos run five to eight reporting systems that were never designed to talk to each other: an ERP for actuals, a CRM for pipeline, Excel forecasting models, and a BI tool someone built three years ago that half the team stopped trusting. Each carries a different version of the truth.
Before anything else works, all of it needs to land in one warehouse. For most mid-market portcos, that means Snowflake or Databricks. The ingestion layer is usually Fivetran or Airbyte: managed connectors that handle extract-and-load without a data engineer writing custom pipeline code for each source.
This is not technically complex. It is operationally disciplined: deciding which systems are authoritative, setting up the connections, and getting data into one place where it can be joined and queried reliably. With the right tooling, it takes four weeks.
A mid-market services portco we worked with had been chasing AI-assisted forecasting for six months. The problem was simpler than anyone wanted to admit. Sales data lived in Salesforce, billing in NetSuite, headcount in a spreadsheet, and nobody had consolidated them. Once they landed in Snowflake through Fivetran connectors, forecasting became tractable within weeks.
Problem 2: Nobody agrees on what "customer" or "revenue" means
This is where month-three death happens.
I have watched portcos build dashboards on consolidated raw data. They look good in demo. Then the board meeting happens. The CFO's revenue number does not match the COO's, which does not match what the CEO submitted to the sponsor. Same source data. Different logic to calculate from it.
Is revenue gross or net of refunds? Recognized or billed? Which customer counts for MRR: contracts signed this month or active subscriptions? If the answers to these questions live in different people's heads or in undocumented SQL, you have a governance problem that no model will fix.
This is what dbt solves. dbt is a transformation and semantic layer that sits between raw warehouse data and downstream consumers. Define "revenue" in dbt once, test it, version-control it, and every report or AI model that pulls from it gets the same answer.
Gartner's 2026 Market Guide for Agentic Analytics put a number to this risk: 60% of agentic analytics projects relying solely on MCP protocols will fail by 2028 because they lack a consistent semantic layer. Without it, models generate confident answers built on wrong definitions. The project does not fail on a technical error. It fails when the board decides the numbers cannot be trusted and shelves it.
The fix is not technically hard. The obstacle is the conversation between the CFO, COO, and data team about what the numbers actually mean. That conversation is uncomfortable. Skipping it is expensive.
Problem 3: The data is stale and the updates are manual
Assume you have done the first two things right. You have consolidated data in a warehouse and a dbt semantic layer that everyone trusts. Now ask: how fresh is the data, and what happens when a pipeline breaks?
For most portcos at this stage, the answer is: data is 24 to 48 hours stale and when a pipeline breaks, someone notices eventually because a dashboard goes blank.
That is not a foundation that can support AI agents making operational decisions.
You need orchestration, either Airflow or Dagster, to schedule and manage the sequence pipelines run in. And you need data quality tests built into dbt that alert the moment something breaks: row counts drop, null rates spike, a key metric moves outside its expected range.
A portco with a two-person data team asked whether they would need to hire before deploying this stack. The answer was no. They were spending roughly 40% of their time firefighting: chasing broken pipelines, reconciling discrepancies, patching things manually. After orchestration and quality testing were in place, that dropped sharply. The same two people held the entire stack, because it now surfaced problems instead of hiding them.
Only now does AI land
The companies that work through these three problems in order can run their first AI use case on a foundation the model can actually trust. Clean, defined, fresh data makes AI outputs auditable. When something looks wrong, there is a semantic layer to check. When a pipeline breaks, alerting catches it before it poisons the inputs.
The Databricks survey of more than 20,000 organizations found that companies using AI governance tooling are 12 times more likely to get AI into production than those that do not. That multiplier is not about the model. It is about whether the foundation under it is trustworthy.
The first AI use case for most portcos is predictive analytics on clean, unified data. Not an agent making decisions. A model that gives a CFO reliable forecast scenarios because the inputs are finally reliable. Everything more ambitious builds from there.
Three questions for operating partners
When a portco tells us they are ready for AI, the first three questions we ask are not about models, vendors, or use cases.
We ask: show me your single source of truth. Show me where your metric definitions live and how they are tested. Show me the last time a pipeline failed and how long it took to find out.
The answers tell us where the portco actually is. Sometimes the foundation is cleaner than expected and we move quickly. Sometimes the answer to all three is "we do not have that," and the honest timeline is six to nine months before AI makes sense.
Either way, the most productive question an operating partner can ask is not "what is your AI strategy?" It is those three. Ask them, be honest about the answers, and the path forward gets clearer.
We run a data-readiness assessment with every portfolio company before scoping any AI work. If you want to know where your portco actually stands, that assessment is where we start.