
Organizations continuously seek robust, flexible, and scalable solutions to handle their diverse data needs in today's rapidly evolving data landscape. Databricks and Microsoft Fabric have emerged as leading platforms, each with strengths and target personas. While they share some similar technical features, their unique approaches to data management make them highly complementary services. This article explores how Databricks and Microsoft Fabric can be used together to create a powerful, integrated data ecosystem, highlighting the benefits and synergies of leveraging both platforms.
Overview of Databricks
Databricks is the inventor of the Lakehouse architecture, an open, unified foundation for all your data. Databricks provides a Data Intelligence Platform that unifies data, AI, and governance in one platform and architecture, enabling organizations to execute their data engineering, data analytics, and AI initiatives on a single powerful, open, secure platform.
The core components of the Databricks platform are seen below.
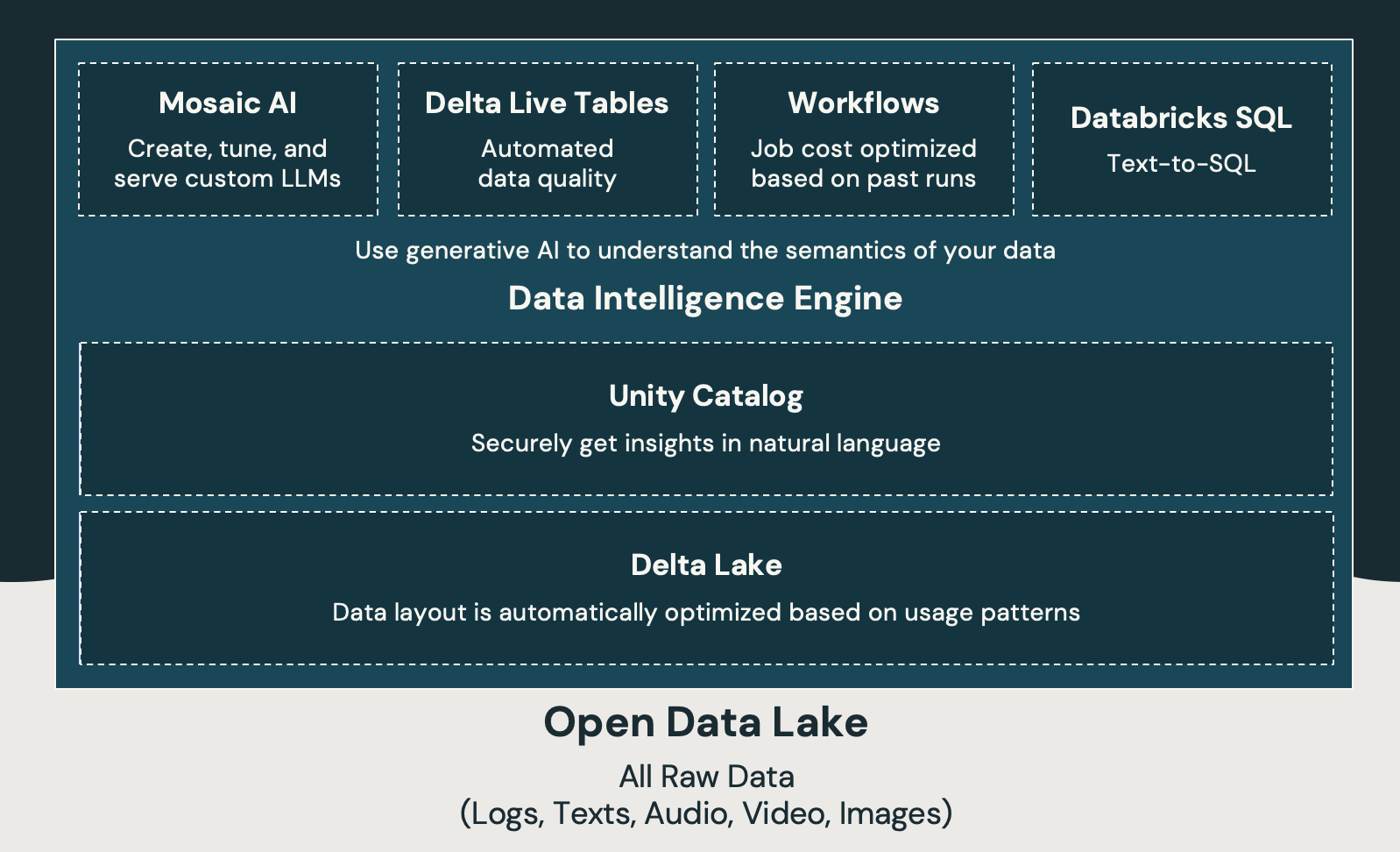
Databricks is built on top of Open-Source technology and has been a pioneer in the data processing, machine learning, and open data format space since its inception. Spark, the core distributed data processing technology, has been the de facto standard for almost a decade. This has powered the platform's core and allowed data engineers and data scientists to easily scale their workloads and do amazing things with data.
Overview of Microsoft Fabric
Microsoft Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution. It encompasses data movement, processing, ingestion, transformation, real-time event routing, and report building. It offers a comprehensive suite of services, including Data Engineering, Data Factory, Data Science, Real-Time Analytics, Data Warehouse, and Databases.
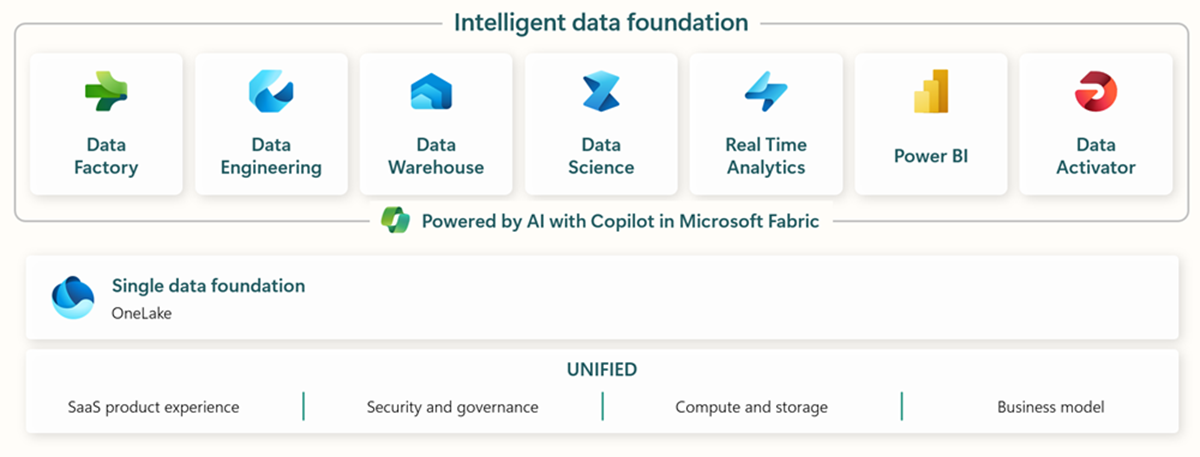
The Fabric solution is built to be user-friendly, which enables greater accessibility to these powerful data technologies for less technical users. It enables organizations with citizen data practitioners to build data products using the same underlying technologies that companies with more advanced data teams have taken advantage of for a while. It’s built on top of the Lakehouse patterns in the form of Azure OneLake in the open Delta Lake format. It stitches together different experiences tailored for data engineers, analysts, data scientists, and others to provide them with a paired-down set of tools and options to allow them to achieve their respective goals.
Databricks + Fabric are aligned and complementary services
From the surface level, it seems like there are a lot of overlapping capabilities between Fabric and Databricks, and that would not be wrong. However, these individual capabilities are not necessarily unique to these two services. Many platforms offer similar suites of services and capabilities, including others within the Microsoft ecosystem (see Synapse). Its more important to look at how the entire architecture and integration is converging in a way that serves the ultimate goal of Databricks to build a truly open and interoperable platform.
Unlike other cloud Databricks deployments, Azure Databricks is a native, first-party interoperable Azure service. The partnership between Microsoft and Databricks allows them to build deeper and tighter integration into their services and roadmaps. You can see this in the choices Microsoft has made when designing the core components of Fabric. A foundational component of the Fabric ecosystem is the Lakehouse. They’ve made it dead simple to create a Lakehouse with a few clicks. This aligns with Databricks and their central argument that a Lakehouse is the best Data Warehouse and the best way to build a future-proof data platform.
One important choice from Microsoft is that they chose to standardize their Lakehouse to use Delta Lake, the storage framework & format pioneered and open-sourced by Databricks. There are a few popular competing options in this space today, between Hudi, Iceberg, and Delta, and there are a lot of benefits in some healthy competition in this space — like pushing each other to improve performance and add more features to get parity with traditional cloud data warehouses. I believe that, ultimately, there will not be a winner in this race and that open interoperability between these formats and frameworks will be the way of the future. That being said, I don’t think a format other than Delta Lake would make sense for Microsoft Fabric, given their long and public partnership with Databricks.
Native Integration is the key!
Another key integration point is that Databricks integrates with Power BI through native connectors. The seamlessness of the integration can be seen in how easily Azure Databricks allows you to publish and start using data in Power BI and the Fabric experience directly from the data explorer — As demonstrated by Databricks CEO Ali Ghodsi here.
Since Azure Databricks is a first-party service co-developed by Databricks and Microsoft, it already natively integrates with many core services within Azure, many of which are already key components of the Fabric experience:
- Azure Active Directory
- ADLS
- Azure Data Factory
- Azure Synapse Analytics
- Power BI
- Azure DevOps
- Azure Virtual Network
- Azure Event Hubs
- Azure Key Vault
- Azure Confidential Computing
By integrating these two, you can take advantage of Databricks best in bread ML and AI capabilities into the Fabric ecosystem. MLFlow and Mosaic ML are critical components of the AI lifecycle that are very mature in the Databricks ecosystem but nascent in the Fabric one. It's not an area that is highlighted much, So I think there will be plenty of development in how these products will be used together. But as of today, using Databricks’ ML and AI Capabilities is currently the best way to build, deploy, and manage production scale workloads within this ecosystem.
Today you can connect data from OneLake into Databricks and vice versa in a few different ways, but it's not as seamless as it could be and not what I would want from a production-grade integration. They currently skirt the best practices for governance through Unity Catalog, so I wouldn’t recommend them if you are reliant on Unity.
These decisions and integrations signal that we will see more native capabilities coming quickly. I think a native Databricks Unity Catalog integration with OneLake, Fabrics' data foundation, would be a critically important addition, enabling more robust use of Unity Catalog’s great governance features outside the native Databricks tooling and experience. Keep a close eye on these two services as they evolve together!
Benefits of Using Both Together
Building a foundation on Lakehouse allows your data estate to be well-managed by integrating these platforms' fine-grained RBAC and ABAC capabilities. It also allows your solid foundation to enable you to take on AI and more advanced analytics use cases as your organization matures its data capabilities. Given their complementary nature, using these products together can give you the following benefits:
- Improved data governance and security
- Increased productivity and collaboration
- Cost efficiency and optimized resource utilization
- Secure Data intelligence — same fine-grained RBAC & ABAC
- An open & extensible platform
Enhanced flexibility and scalability — Fabric and Databricks are targeted at different parts of the data market — if you carefully design a solution to integrate both, you can enable your less technical data practitioners to start building on top of a Lakehouse foundation through Fabric at the same time as your more technical data teams are executing against the robust platform Databricks provides with more fine-grained control over scaling workloads and using DevOps best practices. This can increase productivity and collaboration across these sets of users by allowing each group to use the tools that best suit their needs. Think about Databricks + Fabric: Better Together!
Many data leaders think about products when considering their data platforms; instead, they should rethink their strategy to be centered around an open Lakehouse architecture that enables all use cases and is durable for the long run!
Contact Blue Orange Digital, Your Strategic Data Partner — We would love to discuss your Data Strategy and how these ideas can help evolve it!