Building a Real-Time CDC Pipeline with Kafka and Snowflake (Part 1)
🚀 In a modern enterprise, there are several compelling reasons why you would/should want to replicate changes from one place to another, and even more for doing it constantly, reliably, efficiently, and fast. In this article, we will show how we replicated not one but several databases into Snowflake in real time with a lot of cool features like automatic table replication, schema evolution, and deduplication.
🚲 I know that mentioning Kafka and Kubernetes in the same sentence could feel a little bit overwhelming at first, and while I agree, the right way to start is to Keep It Simple Stupid 💋. So let’s start our journey small, as if we were learning to ride a bike. The beauty of Kubernetes is that we can always turn this Bike into a Ferrari 🚗.
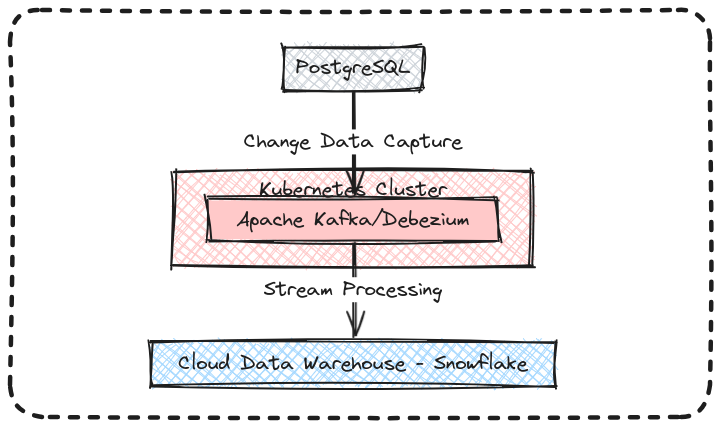
📚 In this 3 part article we’ll present a real time CDC, Change Data Capture, pipeline with Kafka and Debezium to stream changes from a Postgres database to a Snowflake lake house in Real Time. We’ll start small, so let’s begin with a minimal confluent kafka setup in your local machine as you would ideally start as-in a PoC environment.
Part 1 — Install and Deploy Confluent Kafka on Kubernetes
💻 Requirements:
Kubectl + Minikube with 2 cpus and 4G memory
At the time of this tutorial I was running on a very modest 4 cpus 8Gb memory laptop with Linux Ubuntu 22.04, kubectl v1.29.3 and minikube v1.32.0. You should be fine with earlier versions of linux, kubectl and minikube 🙂
Section 1 — Installing kubectl
To run kubectl download and install kubectl for linux, or your OS https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/
1. Download kubectl.
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
2. Install kubectl.
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
3. Check kubectl’s version.
kubectl version --client --output=yaml
Section 2 — Installing Minikube
To deploy kubernetes locally Install and start minikube, we’ll follow instructions in here: https://minikube.sigs.k8s.io/docs/start/.
1. Download minikube.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
2. Install minikube.
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64
3. Check minikube’s version.
minikube version
4. Start minikube.
minikube start
# or dev/local minimum cpu/memory configuration
minikube start --cpus 2 --memory 4096
Section 3 — Deploying Confluent Kafka
In order to deploy confluent Kafka on Kubernetes check out the examples here, https://github.com/confluentinc/confluent-kubernetes-examples, but we’ll provide our pre-configured helm chart for this project:
❄️ https://github.com/gillsantos/streamflake
git clone https://github.com/gillsantos/streamflake.git
📔 IMPORTANT NOTE: Some configurations were made to confluent helm charts in order to enable automatic topic creation and schema evolution.
1. Create a confluent namespace.
kubectl create namespace confluent
2. Set confluent as your current context.
kubectl config get-contexts
kubectl config set-context --current --namespace confluent
3. Set up the Helm Chart.
helm repo add confluentinc https://packages.confluent.io/helm
4. Install Confluent Operator For Kubernetes using Helm.
helm upgrade --install confluent-operator confluentinc/confluent-for-kubernetes --namespace confluent
5. Deploy Confluent Platform with the provided configuration.
kubectl apply -f ./helm/confluent-platform.yaml
# or dev/local minimal configuration
kubectl apply -f ./helm/confluent-platform-dev.yaml
6. Check that the Confluent For Kubernetes pod comes up and is running.
kubectl get pods
7. Check that all Confluent Platform resources are deployed.
kubectl get confluent
8. Finally access control center on your web browser.
# get kubernetes ip
minikube ip
# get exposed port
kubectl describe service -n confluent | grep -i nodeport
And access control center on ip:port.
Or forward desired pod port to your local machine, here are the main ones.
#kubectl port-forward <pod-name> <localhost-port>:<pod-port>
kubectl port-forward schemaregistry-0 8081:8081
kubectl port-forward controlcenter-0 9021:9021
kubectl port-forward connect-0 8083:8083
Voilá! You should see a screen like this one.

🐞 TROUBLESHOOTING makes perfect:
When troubleshooting I personally like the macro-to-micro approach, and believe me, while working on this post I used these A LOT.
# 1. macro (all pods)
kubectl get po -n confluent
# 2. pod specific
kubectl describe pod connect-0
# 3. log error messages
kubectl logs connect-0 | grep -i error
♻️ WHEN DONE:
In case you need to remove everything we’ve done, or want to do it all over again here is how to clean up everything.
In case you want to stick around, I recommend you just Stop Minikube and wait until our next episode (Just step 4).
1. Delete kubernetes resources.
kubectl delete -f ./helm/confluent-platform.yaml
# or
kubectl delete -f ./helm/confluent-platform-dev.yaml
2. Check if ports are being forwarded.
ps -aux | grep kubectl
# Kill process
pkill kubectl
3. Uninstall Confluent Operator.
helm uninstall confluent-operator
4. Stop minikube (if necessary).
minikube stop
5. Delete minikube (⚠️ This will destroy everything deployed).
minikube delete
🎬 To be continued…
This is the first of a three-part article. Stay tuned for what’s next!
Contact us to help your organization implement this type of solution today!