OpenLineage and Airflow Simplify Data Lineage

The GDPR (General Data Protection Regulation), asks organizations to implement data lineage for a clear understanding of the data used within the systems. Paying attention to data lineage not only helps organizations comprehend complex issues within their data operations but also helps explain and justify errors which your users might stumble upon.
Primarily, the function of data lineage remains to keep track of data since its extraction from the source, the transformations that follow, and loading into the destination. Staying updated on these phases data goes through allows businesses to make wiser decisions. Not knowing where data originated from and the state of those resources could create a mess.
However, considering the vast amount of data, complexity, and its ever-changing state proves challenging with the implementation of data lineage, and requires tools and platforms that adapt to different industries with ease. Today, we’ll discuss the execution of a data lineage strategy using Airflow and OpenLineage.

What is Data Lineage and how do you implement it?
The data within an organization undergoes several processes. Data lineage attempts to portray this journey of data, from the initial collection phase to the final state of deletion. In short, data lineage is concerned with the identification, understanding, tracking, and representation of the data state as it changes and the reasons why.
Data lineage includes the sophisticated relationship between jobs and datasets being processed in a pipeline. This involves the relationship among consumers and producers in datasets, and the input and output collected during each job. Data lineage is best represented in a visual form that simplifies its complex nature.
Implementing data lineage in your organization early gives you advantages for the long term. Even though it requires time and experts to deal with its intricacies, it is essential for most businesses. We’ll try to explain its implementation in under four steps:
- Determine the data elements: Collect information from users to locate the essential elements of your business.
- Find the origin: Gather information about the identified elements from their origin to the current state.
- List sources and documents: Include all the resources to data elements, sources, and related materials into a spreadsheet.
- Start mapping: Turn all the known systems into visual maps, and create a large map to include all of them.
What is OpenLineage?
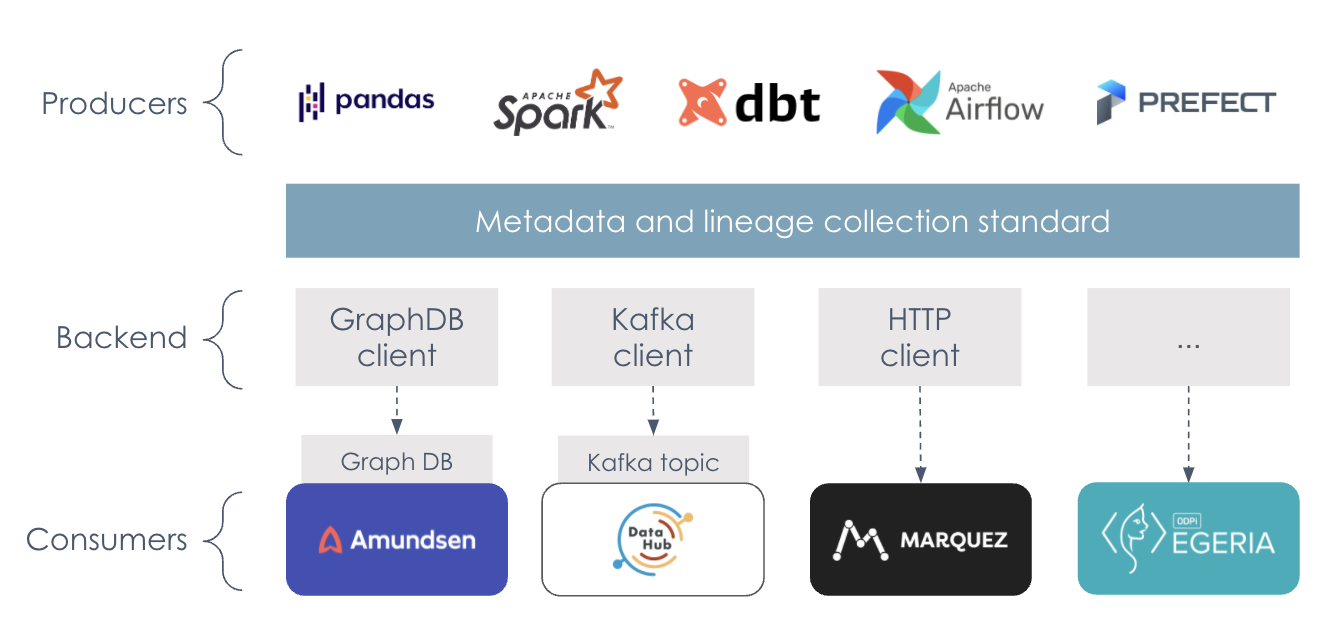
OpenLineage is not a single tool. It functions as a platform encompassing multiple libraries for common languages, multi-functional integrations, a metadata reference implementation known as Marquez, and much more. As the name suggests, the purpose of OpenLinage is the gathering and analysis of data lineage, while data is being processed through pipelines.
As an open-source project initiated by Datakin, it was built with the help of many contributions, as seen in the image below. Among them are also dbt, Apache Spark, and Marquez.

Traditionally, organizations use data fragmentation which offers some kind of assistance in how the data is organized and managed. Answering fundamental questions that surround data management is challenging with a fragmented data infrastructure.
What is the source of data, who owns it, and what has changed? Is there a schema for us to check? How often is this data updated and where does it go? Finding answers is easier with data lineage.
OpenLineage focuses on reducing fragmentation to help create useful and practical solutions regarding data compliance, operations, and governance.

OpenLineage is architectured with three layers in mind, considering the flow of metadata from producers to consumers. It goes like this:
- Lineage metadata is captured on tools concerned with data transformation and dataset production.
- Lineage information is processed towards the selected backends.
- The lineage metadata information is served to users who seek it.
Using Apache Airflow and OpenLineage
Monitoring and scheduling workflows get challenging as data expands. Airflow is an open-source tool that assists with the monitoring, authoring, and visualization of workflows, data pipeline processes, code progress, success status, etc. Airflow turns workflows into DAGs (Directed Acyclic Graph) which display tasks in such a way that makes their dependencies and relationships observable.
These graphs are written in Python, specifying tasks and their details. The data and tasks included in these scripts don’t have to belong to the same systems or uses. Neither do the tasks have to depend on each other. What matters is for tasks to be executed in their order.
However, by using Airflow alone the management of inter-DAG dependencies and a display of the execution processes remains sophisticated. The integration of Airflow with OpenLineage brings metadata lineage DAGs in a manageable and visible graph while keeping track of the historical runs for each of them.
In a Nutshell
Large, mid-sized, and small organizations, all need to maintain the quality of their data in order to resolve problems and keep track of their data flow. To achieve this, there are three characteristics data should have: freshness, quality, and availability. Data lineage assists in fulfilling these characteristics by tracking the “footsteps” of data within your systems.
A combination of business intelligence tools, platforms, and data science integrations makes data and metadata presentable and manageable. At Blue Orange, we strive to create an environment where our clients can get a clear picture of their data as it is running and base their decisions on real numbers. Contact us to learn more.



{kind=link}