
Last week, Blake and I flew down to Atlanta for FabCon and SQLCon 2026 at the Georgia World Congress Center. This was the third annual Fabric Community Conference and the first time it ran alongside SQLCon, bringing 8,000+ attendees, 300 sessions, 22 full-day workshops, and 230+ speakers under one roof. The energy was different this year. Not "we are excited about the vision" energy. More like "we are shipping this to production next quarter" energy.
I wanted to put together a thorough recap for our clients and the broader data community because the volume of announcements was staggering. Microsoft dropped 120+ features and updates across governance, compute, AI, real-time intelligence, and data integration. Some of these are incremental. Others fundamentally change how we will architect data platforms for our clients in 2026 and beyond.
Here is everything that matters, organized so you can jump straight to what is relevant to your stack.
Table of contents
- The big picture: Fabric as the unified data platform
- OneLake: Interoperability, security, and the open data layer
- Runtime 2.0 and data engineering upgrades
- Fabric IQ, ontologies, and the semantic intelligence layer
- AI agents: Data agents and operations agents hit GA
- NVIDIA partnership: Physical AI comes to Fabric
- Real-time intelligence: Maps, events, and streaming
- Database Hub and the SQL convergence story
- Data Factory: Mirroring, copy jobs, and migration
- Power BI: Direct Lake on OneLake goes GA
- Developer experience: Git, CLI, and MCP
- Governance and security
- Data warehouse updates
- What this means for our clients
The big picture: Fabric as the unified data platform
Two and a half years after reaching general availability, Microsoft Fabric now serves more than 31,000 customers and continues to grow at roughly 60% year-over-year. That makes it the fastest-growing data platform in Microsoft's history by their own metrics.
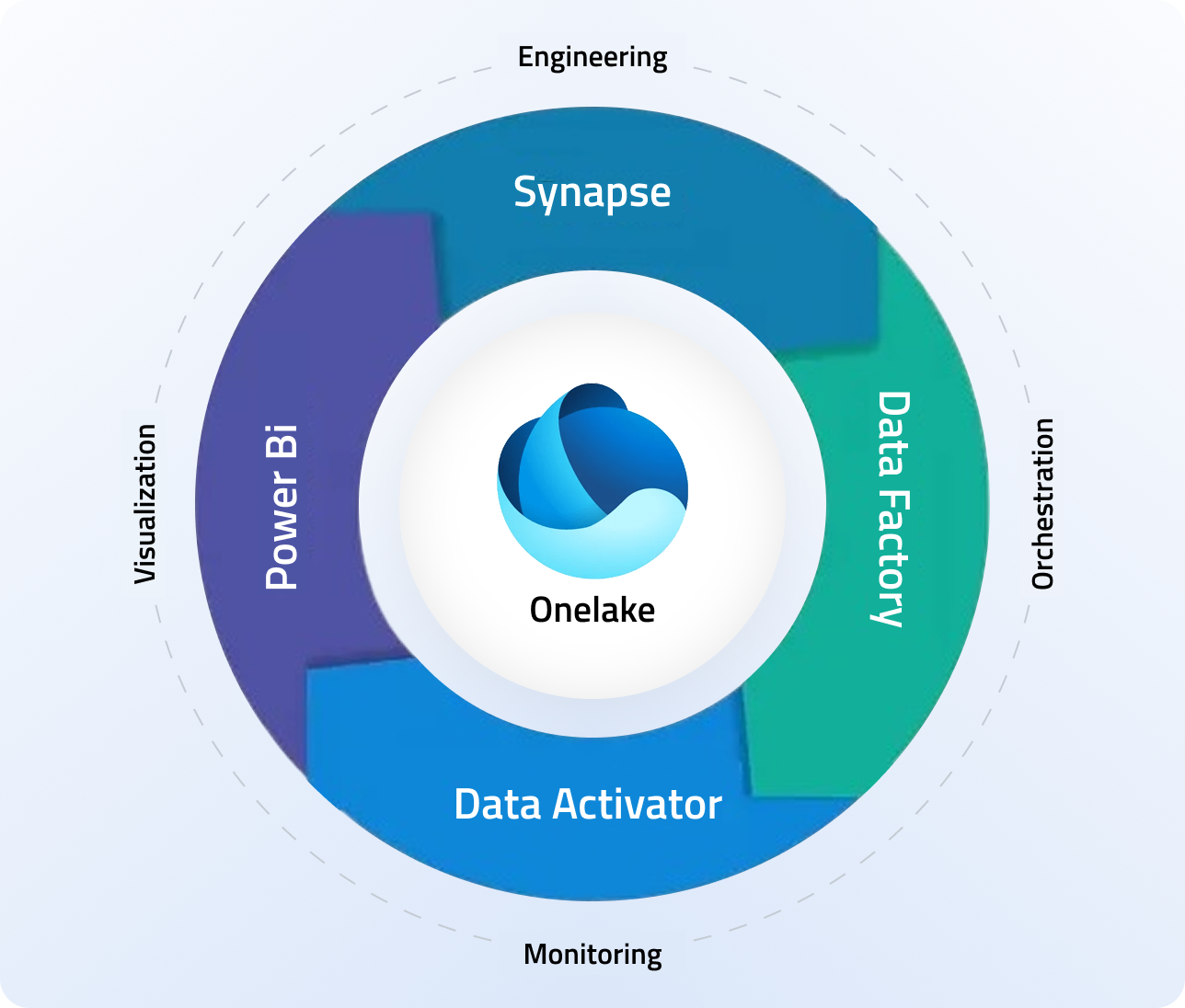
The overarching theme of FabCon 2026 was convergence. Microsoft is no longer positioning Fabric as "just" an analytics platform. They are pulling databases, real-time intelligence, AI agents, and enterprise planning into a single architecture with OneLake as the unified storage layer. Arun Ulag, president of Azure Data, put it plainly in his keynote blog: they are unifying transactional, operational, and analytical data under one consistent architecture.
For those of us building production data platforms, this is the part that matters. The platform sprawl that has defined enterprise data for the past decade is being actively compressed. Whether you run on Snowflake, Databricks, or a hybrid Azure stack, the interoperability announcements at FabCon signal that Microsoft wants OneLake to be the gravitational center.

OneLake: Interoperability, security, and the open data layer
This was the headline story for our team. The OneLake announcements touched every layer of the stack, from connectivity to governance.
Snowflake interoperability (GA)
Snowflake interoperability is now generally available. Joint customers can bidirectionally read Iceberg data managed by either Snowflake or Fabric, and Snowflake-managed Iceberg tables can now be natively stored in OneLake. For clients running dual-platform architectures, this eliminates a painful class of data movement problems. You define it once; both platforms read it.
Azure Databricks Unity Catalog integration (public preview)
The ability to natively read from OneLake through Azure Databricks Unity Catalog is now in public preview. Two-way interoperability (write and store) is in active development. This is a significant step toward making OneLake a true multi-engine storage layer rather than a Microsoft-only construct.
Shortcut transformations (GA)
Shortcut transformations reached general availability. You can now automatically transform data as it enters OneLake or moves between data items, including format conversion to Delta Lake and AI-powered transformations like summarization, translation, and document classification. A new Excel-to-Delta table transformation is also in preview, which solves a surprisingly common ingestion pain point.
Materialized lake views (GA)
Materialized lake views are generally available. These simplify medallion architecture implementation in Spark SQL and PySpark and enable always-up-to-date pipelines with no manual orchestration. Multiple schedules per view and PySpark authoring support via the DataFrameWriter API round out the feature set. For teams building layered data products, this removes a significant chunk of orchestration boilerplate.
OneLake security (GA, rolling out in coming weeks)
OneLake security is going GA with a unified role-based access control model, row- and column-level enforcement, and a single permission model that follows the data across all analytics experiences. Third-party engines can also enforce these policies through the new authorized engine model.
OneLake File Explorer for Windows (GA)
The OneLake file explorer is now GA, letting users browse workspaces and manage files like OneDrive. Simple, but it removes friction for less technical users who need to interact with lakehouse data.
Runtime 2.0 and data engineering upgrades
The data engineering announcements were substantial. Runtime 2.0 is now in preview, purpose-built for large-scale computation with Apache Spark 4.0, Delta Lake 4.0, Java 21, Python 3.12, Scala 2.13, and Azure Linux Mariner 3.0. This is not a minor version bump. Spark 4.x and Delta Lake 4.x represent meaningful performance and feature improvements for anyone running heavy ETL or ML workloads.
Compute and performance highlights
- Custom live pools (GA): Dedicated, pre-warmed Spark pools with preinstalled libraries, scheduling, and network isolation. This is a game-changer for teams that need predictable job start times.
- Native execution engine with Z-Order and liquid clustering (GA): 20-27% performance improvement on large datasets with advanced data layout techniques.
- Resource profiles (GA): Workload-aware automatic compute configuration recommendations.
- Job concurrency and queue monitoring (GA): Visibility into active, queued, and completed Spark jobs with bottleneck analysis.
Notebooks and developer tooling
- Copilot for data engineering and data science (GA): Context-aware notebook assistance with code generation, error analysis, and troubleshooting. The new agentic experience understands your workspace, attached Lakehouse, and execution environment.
- Fabric Notebook custom agent in VS Code (GA): A Fabric-native AI development agent with workspace, runtime, and Lakehouse awareness.
- New kernels in VS Code (GA): Python, Scala, and Spark SQL kernels alongside PySpark.
- AutoML in Fabric (GA): Fully integrated UI for experiment configuration, model tracking, performance comparison, and deployment.
Fabric IQ, ontologies, and the semantic intelligence layer
This was arguably the most forward-looking set of announcements. Fabric IQ is Microsoft's answer to the "AI data readiness gap" that, by their own data, keeps roughly 50% of agentic AI projects stuck in proof-of-concept.
Amir Netz, CTO of Microsoft Fabric, described it this way: "Semantics help AI understand entities, relationships, rules and intent." Fabric IQ transforms raw data into structured operational knowledge by organizing data in business language, defining entities like customers, locations, and assets, and binding them to real-time and historical data.
Ontologies via MCP (preview)
Fabric IQ ontologies will be accessible through an MCP server in preview. This means agents can discover, understand, and act on the semantic layer. Ontology Rules now integrate Fabric Activator directly, enabling condition-based automated responses within the semantic layer itself.
Planning in Fabric IQ (new)
A new enterprise planning capability lets organizations create plans, budgets, forecasts, and scenario models directly on top of Fabric's semantic models. Combined with ontologies, this gives organizations a complete view of historical, real-time, and forward-planning data from a single source.
Graph in Fabric (GA, coming weeks)
Graph capabilities are reaching GA with billion-scale support, enhanced data agent integration, and shortest-path queries. This opens up use cases around supply chain mapping, customer relationship analysis, and fraud detection that previously required separate graph database infrastructure.
AI agents: Data agents and operations agents hit GA
Fabric data agents are now generally available. These are virtual analysts grounded in domain-specific data sources including Lakehouse, Warehouse, semantic models, Eventhouse, SQL databases, and mirrored databases. They support publishing, sharing, Git integration, and deployment pipelines.
Two distinct agent types now operate on shared context:
- Data agents provide conversational natural language access to business data, grounded in the ontology.
- Operations agents continuously monitor conditions, identify patterns, and execute autonomous actions within human-defined guardrails.
Advanced security and governance for data agents is in preview, with Purview integration for auditing, eDiscovery, data lifecycle management, and communications compliance.
Blake and I spent a good amount of time in the agent-focused sessions. The key takeaway: these are not chatbot wrappers. They are production-grade components with real governance, real security, and real deployment pipelines. For our clients exploring agentic AI, this is the most enterprise-ready agent framework we have seen on any platform.

NVIDIA partnership: Physical AI comes to Fabric
Microsoft deepened its partnership with NVIDIA, positioning Fabric as the operational backbone for what they call "Physical AI." The integration combines Fabric's Real-Time Intelligence and Fabric IQ with NVIDIA Omniverse libraries for digital twins and predictive maintenance.
A private preview is launching in April with Omniverse 3D scenes embedded directly in Fabric Real-Time Dashboards, featuring bidirectional cross-highlighting. The Vanderlande case study they showed, an AI-powered 3D airport digital twin, was one of the most compelling demos at the conference. For clients in manufacturing, logistics, and supply chain, this integration opens up a class of operational intelligence that was previously custom-built and expensive.
Real-time intelligence: Maps, events, and streaming
The Real-Time Intelligence stack got several production-ready features.
- Maps in Fabric (GA): Native geospatial intelligence for spatial decision-making, integrated with real-time analytics. Turn large volumes of location-based data into interactive, real-time visual insights.
- Business events (preview): Event-driven architecture detecting business-level occurrences like "customer at risk" or "equipment needs maintenance."
- Eventstreams Deltaflow (preview): Build event-driven, real-time applications triggered by database changes.
- SQL Operator in Eventstream (GA, early April): SQL logic over streaming data with content-based routing.
- Anomaly detector full-item experience (GA): Complete anomaly detection interface with the ability to feed outputs into event pipelines.
- Live update for real-time dashboards (GA): Dynamic dashboard refresh with streaming data.
- Copilot for real-time dashboard visuals (preview): Generate dashboard visuals using natural language.
Database Hub and the SQL convergence story
The convergence of SQL Server and Fabric was a running theme. Database Hub in Fabric launched as an early release offering, providing a single control plane across Azure SQL, Azure Cosmos DB, Azure Database for PostgreSQL, MySQL, SQL Server via Azure Arc, and Fabric Databases. Agent-assisted management includes built-in observability, delegated governance, and Copilot-powered insights.
A new savings plan for databases offers up to 35% savings compared to pay-as-you-go pricing on select services.
SQL Database in Fabric is now GA, and data writeback supports Fabric SQL databases, Fabric warehouses, and Fabric lakehouses for files. For heavy read/write reporting scenarios, SQL database is the recommended data source.
Migration assistants are now in public preview for moving from Azure Data Factory, Azure Synapse Analytics, and Azure SQL to Fabric. The SQL database migration assistant imports schemas through DACPACs, identifies compatibility issues with AI assistance, and guides teams through assessment and data copy workflows.

Data Factory: Mirroring, copy jobs, and migration
The Data Factory announcements were deep and practical.
Mirroring expansion
- Oracle and SAP Datasphere mirroring (GA): Real-time data synchronization from Oracle and SAP systems.
- SharePoint lists mirroring (preview): Synchronize SharePoint list data into OneLake.
- Azure Database for MySQL mirroring (preview): Support for MySQL database mirroring.
- Dremio and Azure Monitor mirroring (preview/coming soon): Broader ecosystem connectivity.
- Extended mirroring capabilities (preview): Change Data Feed generation and Snowflake view mirroring as a paid option.
- Mirrored databases now support up to 1,000 tables (GA).
Copy job and Dataflow Gen2
- Incremental copy now supports 10+ new connectors including Google Cloud Storage, DB2, ODBC, Fabric Lakehouse tables, and Amazon RDS instances.
- AI-powered prompt transform (GA): Create columns via natural language prompts in Dataflows.
- Pipeline expression Copilot (GA): Generate complex expressions using natural language.
- Mapping Data Flows arriving by June 2026 for Spark-scale transformations, enabling Dataflows to run natively in Fabric Data Factory.
- Zero CU cost when no data changes for incremental loads.
dbt integration improvements (preview)
Direct GitHub repository integration, expanded logging to OneLake (removing the 1 MB limit), and public dbt package support.
Migration assistant
A new migration assistant simplifies the move from Azure Data Factory to Fabric, offering feature parity and seamless transition paths.
Power BI: Direct Lake on OneLake goes GA
The Power BI March 2026 update coincided with FabCon and delivered several significant features.
- Direct Lake on OneLake (GA): This is a big deal. Organizations can now read directly from OneLake with native security enforcement, richer cross-item modeling, and import-class performance without data movement. Microsoft recommends Direct Lake on OneLake for most use cases, with Direct Lake on SQL reserved for delegated identity mode scenarios.
- Translytical task flows (GA): Users can update records and trigger workflows directly within reports without navigation. This blurs the line between reporting and operational applications.
- TMDL View on web (preview): Code-first modeling experience enabling browser-based script modifications to semantic models.
- DAX user-defined functions: Now support 256 parameters (up from 12), with new type hints and an INFO.USERDEFINEDFUNCTIONS() function.
- AI Narrative auto-refresh: Automatic updates when slicers change, eliminating manual refresh clicks.
- Modern visual defaults (preview): Updated Fluent 2-aligned styling.
One fun note from the conference: Gustavo Bavia won the Power BI DataViz World Championships at FabCon. The competition visualizations were impressive.
Developer experience: Git, CLI, and MCP
Microsoft is investing heavily in making Fabric a first-class development platform. The developer experience announcements were some of the most practically useful at the conference.
Git integration
- Branched workspace (preview): A new developer experience that simplifies feature workspace management with clearer visual cues and richer context.
- Selective branching (preview): Choose only the items you need for a feature branch, reducing clutter in the target workspace.
- Compare code changes (preview): Side-by-side diff view for workspace and repository changes.
- Lakehouse auto-binding in Git (GA): Notebooks automatically resolve the correct lakehouse across dev, test, and prod environments.
- Notebook resources folder support in Git (GA): Version notebook dependencies and supporting files with .gitignore exclusion rules.
CLI and automation
- Fabric CLI v1.5 (GA): Semantic model refresh, report rebinding, and deployment scripting.
- CI/CD deployments from CLI (GA): Single-command workspace deployment with item rebinding.
- Bulk import/export item definition APIs (preview): Programmatic export and import of Fabric item definitions for workspace migration and CI/CD integration.
MCP integration
- Fabric MCP Local (GA): Open-source local server connecting AI coding assistants like GitHub Copilot directly to Fabric.
- Fabric Remote MCP (public preview): Cloud-hosted execution engine for authenticated actions in Fabric. Agents can create workspaces, manage permissions, and work with item definitions.
- Agent skills for Fabric (open source): Plugins enabling natural language commands in GitHub Copilot terminal.
Fabric Jumpstart
A new Fabric Jumpstart offering provides reference architectures and single-click deployments for datasets, notebooks, pipelines, and reports. This accelerates time-to-value for new Fabric implementations.
Governance and security
Security and governance received significant investment across the board.
- OneLake Catalog Govern for admins (GA): Admin tools to govern and secure data estates within Fabric in one place, with capacity, workspace activity, and protection metrics.
- Data Loss Prevention for Fabric (preview): Extends restrict-access action to Warehouses, KQL databases, SQL databases, Lakehouses, and Semantic Models.
- Purview DSPM for AI (preview): Visibility and governance for AI interactions involving Fabric Copilots and data agents.
- Network security: Resource Instance Rules (preview) for controlling inbound access, workspace-level IP firewall rules (GA), and outbound access protection extended to 15+ Fabric items.
- Customer-managed keys now compatible with BYOK-protected capacities.
- OneLake Catalog Search API and MCP Tool (preview): Cross-workspace asset discovery through a single search request with free-text matching.
- Workspace tags (GA): Metadata tagging at workspace level for discovery and governance, supporting up to 10 tags per workspace.
Data warehouse updates
The Fabric Data Warehouse got several practical improvements.
- Fabric Warehouse custom SQL pools (preview): Dedicated compute resources for specific workloads, giving workspace administrators fine-grained control over SQL compute allocation.
- Warehouse recovery (preview): Restore dropped warehouses with data, schemas, snapshots, permissions, and queries intact.
- Analyze unstructured text with T-SQL AI functions (preview): Process text data using SQL.
- COPY INTO and OPENROWSET for OneLake (GA): Load data directly from OneLake sources.
- SQL audit logs (GA): Comprehensive query and activity logging.
- Alerts and actions (GA): Monitor warehouse health and trigger automated responses.

What this means for our clients
Blake and I walked away from FabCon with a clear picture of where the platform is heading, and it aligns with the conversations we are already having with our clients.
If you are running a hybrid or multi-cloud data platform, the OneLake interoperability story just got real. Snowflake bidirectional Iceberg support in GA, Databricks Unity Catalog integration in preview, and expanded mirroring for Oracle, SAP, and MySQL mean that OneLake is becoming a viable multi-engine storage layer. We are already designing architectures around this for several active engagements.
If you are exploring agentic AI, Fabric data agents and operations agents are the most production-ready agent framework we have evaluated. With GA status, Purview governance, deployment pipelines, and grounding in the Fabric IQ ontology, these are not science projects. They are deployable, governable AI components.
If you are modernizing your data warehouse, the combination of custom SQL pools, migration assistants, and Runtime 2.0 makes the path from legacy platforms to Fabric more straightforward than it was even six months ago.
If you care about governance (and you should), OneLake security going GA with unified RBAC, row-level and column-level controls, and third-party engine enforcement is a meaningful step toward centralized data governance that actually works across multiple compute engines.
The pace of innovation on Fabric is unlike anything we have seen on a data platform. The community in Atlanta was energized, the conversations were technical and specific, and the roadmap is aggressive. We will be publishing deeper dives on several of these features in the coming weeks as we validate them in production for our clients.
If you want to talk about how any of these announcements affect your data strategy, reach out to our team. We are building on this platform every day.
Colin Van Dyke is the CTO at Blue Orange Digital, a data engineering and AI consultancy. Blue Orange Digital builds production-grade data platforms on Snowflake, Databricks, AWS, and of course Azure and Fabric for organizations that need measurable impact, not slide decks.
Sources and further reading:
- FabCon and SQLCon 2026: Unifying databases and Fabric on a single data platform (Arun Ulag, Azure Blog)
- FabCon and SQLCon 2026: What's new in Microsoft OneLake (Microsoft Fabric Blog)
- Fabric March 2026 Feature Summary (Microsoft Fabric Blog)
- Trusted AI starts with Microsoft Fabric: Unified real-time intelligence and IQ context (Microsoft Fabric Blog)
- Fabric Data Factory at FabCon Atlanta: Built for modern data integration (Microsoft Fabric Blog)
- Power BI March 2026 Feature Summary (Microsoft Power BI Blog)
- Microsoft Expands Fabric for Enterprise AI, Deepens NVIDIA Partnership (Yahoo Tech)
- FabCon 2026 Official Site

PE-Grade Data & AI
Assessment Platform
Blueprint gives operating partners a clear, benchmarked view of data and AI readiness across portfolio companies—in days, not months. Start with a free self-service questionnaire or connect environments for automated infrastructure scanning.
Explore Blueprint
Blueprint Assess
Self-service questionnaire for rapid portfolio triage
- 10-minute guided assessment
- Benchmarked maturity scores across 6 dimensions
- Prioritized recommendations with estimated ROI
- No environment access required
- Shareable PDF report for deal teams
Blueprint Scan
Automated read-only infrastructure scanner
- Connects to Databricks, Snowflake & Azure Fabric
- SOC 2 Type II & ISO 27001 (pending)
- Zero data movement — read-only metadata analysis
- Cost optimization & architecture recommendations
- Deployment-ready modernization roadmaps